Python basics
Objectives
Knowing what types exist
Knowing the most common data structures: lists, tuples, dictionaries, and sets
Creating and using functions
Knowing what a library is
Knowing what
importdoesBeing able to “read” an error
Motivation for Python
Free
Huge ecosystem of examples, libraries, and tools
Relatively easy to read and understand
Similar in scope and use cases to R, Julia, and Matlab
Basic types
# int
num_measurements = 13
# float
some_fraction = 0.25
# string
name = "Bruce Wayne"
# bool
value_is_missing = False
skip_verification = True
# we can print values
print(name)
# and we can do arithmetics with ints and floats
print(5 * num_measurements)
print(1.0 - some_fraction)
Python is dynamically typed: We do not have to define that an integer is an
int, we can use it this way and Python will infer it.However, one can use type annotations in Python (see also mypy).
Now you also know that we can add
# commentsto our code.
Data structures for collections: lists, dictionaries, sets, and tuples
# lists are good when order is important
scores = [13, 5, 2, 3, 4, 3]
# first element
print(scores[0])
# we can add items to lists
scores.append(4)
# lists can be sorted
scores.sort()
print(scores)
# dictionaries are useful if you want to look up
# elements in a collection by something else than position
experiment = {"location": "Svalbard", "date": "2021-03-23", "num_measurements": 23}
print(experiment["date"])
# we can add items to dictionaries
experiment["instrument"] = "a particular brand"
print(experiment)
if "instrument" in experiment:
print("yes, the dictionary 'experiment' contains the key 'instrument'")
else:
print("no, it doesn't")
Listsare good when order is important, and it needs to be changedDictionariesare mappings key→value.Setsare useful for unordered collections where you want to make sure that there are no repetitions.There are also
tuplesthat are similar to lists but their items cannot be modified.
You can put:
dictionaries inside lists
lists inside dictionaries
dictionaries inside dictionaries
lists inside lists
tuples inside …
…
Iterating over collections
Often we wish to iterate over collections.
Iterating over a list:
scores = [13, 5, 2, 3, 4, 3]
for score in scores:
print(score)
# example with f-strings
for score in scores:
print(f"the score is {score}")
We don’t have to call the variable inside the for-loop “score”. This is up to us. We can do this instead (but is this more understandable for humans?):
scores = [13, 5, 2, 3, 4, 3]
for x in scores:
print(x)
Iterating over a dictionary:
experiment = {"location": "Svalbard", "date": "2021-03-23", "num_measurements": 23}
for key in experiment:
print(experiment[key])
# another way to iterate
for (key, value) in experiment.items():
print(key, value)
Functions
Functions are like reusable recipes. They receive ingredients (input arguments), then inside the function we do/compute something with these arguments, and they return a result.
def add(a, b): result = a + b return result
Together we write a function which sums all elements in a list:
def add_all_elements(sequence): """ This function adds all elements. This here is a docstring, a documentation string for a function. """ s = 0.0 for element in sequence: s += element return s measurements = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print(add_all_elements(measurements))
We reuse this function to write a function which computes the mean:
def arithmetic_mean(sequence): # we are reusing add_all_elements written above s = add_all_elements(sequence) n = len(sequence) return s / n measurements = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] mean = arithmetic_mean(measurements) print(mean)
Functions can call other functions. Functions can also get other functions as input arguments.
Functions can return more than one thing:
def uppercase_and_lowercase(text): u = text.upper() l = text.lower() return u, l some_text = "SequenceOfCharacters" uppercased_text, lowercased_text = uppercase_and_lowercase(some_text) print(uppercased_text) print(lowercased_text)
Why functions? Less repetition but also simplify reading and understanding code.
Reading error messages
Here we introduce a mistake and we together try to make sense of the traceback:
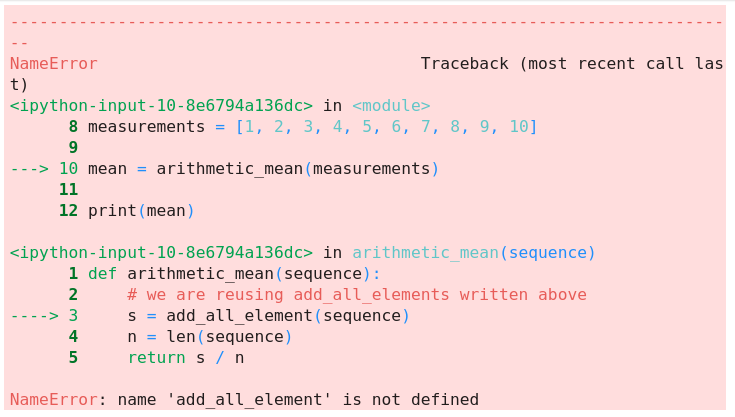
Example error traceback. Can you explain the error?
Libraries
We can look at libraries as collections of functions. We can import the libraries/modules and then reuse the functions defined inside these libraries.
Try this:
import numpy
measurements = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = numpy.std(measurements)
print(result)
This means numpy contains a function called std which apparently computes the standard deviation
(check also its documentation).
Often you see this in tutorials (the module is imported and renamed to a shortcut):
import numpy as np
result = np.std([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
It is possible to create own modules to collect own functions for reuse.
Great resources to learn more
Real Python Tutorials (great for beginners)
The Python Tutorial (great for beginners)
The Hitchhiker’s Guide to Python! (intermediate level)
Exercises
Exercise: create a function that computes the standard deviation
Arithmetic mean:
\[\bar{x} = \frac{1}{N} \sum_{i=1}^N x_i\]Standard deviation:
\[\sqrt{ \frac{1}{N} \sum_{i=1}^N (x_i - \bar{x})^2 }\]In other words the computation is similar but we need to sum over squares of differences and at the end take a square root.
Take this as a starting point:
# we have written this one together previously def arithmetic_mean(sequence): s = 0.0 for element in sequence: s += element n = len(sequence) return s / n def standard_deviation(sequence): # here we need to do some work: # mean = ? # s = ? n = len(sequence) return (s / n) ** 0.5
If this is the input list:
measurements = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Then the result would be: 2.872…
Solution 1 (longer but hopefully easier to understand)
# we have written this one together previously
def arithmetic_mean(sequence):
s = 0.0
for element in sequence:
s += element
n = len(sequence)
return s / n
# notice how this function reuses the other
def standard_deviation(sequence):
mean = arithmetic_mean(sequence)
s = 0.0
for element in sequence:
s += (element - mean) ** 2
n = len(sequence)
return (s / n) ** 0.5
Solution 2 (more compact)
def arithmetic_mean(sequence):
return sum(sequence) / len(sequence)
def standard_deviation(sequence):
mean = arithmetic_mean(sequence)
s = sum([(x - mean) ** 2 for x in sequence])
n = len(sequence)
return (s / n) ** 0.5
Exercise: working with a dictionary
We have this dictionary as a starting point:
grades = {"Alice": 80, "Bob": 95}
Add the grades of few more (fictious) persons to this dictionary.
Print the entire dictionary.
What happens when you add a name which already exists (with a different grade)?
Print the grade for one particular person only.
What happens when you try to print the result for a person that wasn’t there?
Try also these:
print(grades.keys()) print(grades.values()) print(grades.items())
Solution
We can add more people like this:
grades["Craig"] = 56
grades["Dave"] = 28
grades["Eve"] = 75
Print the entire dictionary with:
print(grades)
We get:
{'Alice': 80, 'Bob': 95, 'Craig': 56, 'Dave': 28, 'Eve': 75}
Adding an entry which already exists updates the entry (please try it).
Printing the result for one particular person:
print(grades["Eve"])
Printing the result for a person which does not exists, gives a KeyError.
The outputs of these three:
print(grades.keys())
print(grades.values())
print(grades.items())
… are either the only the keys or only the values, or in the case of items(),
key-value pairs (tuples):
dict_keys(['Alice', 'Bob', 'Craig', 'Dave', 'Eve'])
dict_values([80, 95, 56, 28, 75])
dict_items([('Alice', 80), ('Bob', 95), ('Craig', 56), ('Dave', 28), ('Eve', 75)])
The exercises below use if-statements.
Optional exercise/ homework: removing duplicates
This list contains duplicates:
measurements = [2, 2, 1, 17, 3, 3, 2, 1, 13, 14, 17, 14, 4]
Write a function which removes duplicates from the list and sorts the list. In this case it would produce:
[1, 2, 3, 4, 13, 14, 17]
Solution 1 (longer but hopefully easier to understand)
The function sorted sorts a sequence but it creates a new sequence.
This is useful if you need a sorted result without changing the original sequence.
We could have achieved the same result with list.sort().
def remove_duplicates_and_sort(sequence):
new_sequence = []
for element in sequence:
if element not in new_sequence:
new_sequence.append(element)
return sorted(new_sequence)
Solution 2 (more compact)
Converting to set removes duplicates. Then we convert back to list:
def remove_duplicates_and_sort(sequence):
new_sequence = list(set(sequence))
return sorted(new_sequence)
Optional exercise/ homework: counting how often an item appears
Back to our list with duplicates:
measurements = [2, 2, 1, 17, 3, 3, 2, 1, 13, 14, 17, 14, 4]
Your goal is to write a function which will return a dictionary mapping each number to how often it appears. In this case it would produce:
{2: 3, 1: 2, 17: 2, 3: 2, 13: 1, 14: 2, 4: 1}
Solution 1 (longer but hopefully easier to understand)
def how_often(sequence):
counts = {}
for element in sequence:
if element in counts:
counts[element] += 1
else:
counts[element] = 1
return counts
Solution 2 (more compact)
The point of this solution is to show that for such common operations, ready-made functions and objects already exist and is is worth to check out the documentation about the collections module.
from collections import Counter, defaultdict
def how_often_alternative1(sequence):
return dict(Counter(sequence))
def how_often_alternative2(sequence):
counts = defaultdict(int)
for element in sequence:
counts[element] += 1
return dict(counts)